Global Azure Bootcamp 2024 v Praze
Již v pátek se koná tradiční celosvětová akce Global Azure Bootcamp. Díky organizátorům Update Conference společně s firmou HAVIT a WUG Praha se můžete v pátek osobně účastnit setkání v pražském Microsoftu, kde na vás čeká 12 přednášek rozdělených do dvou místností. Těšit se můžete i na mou přednášku o Pokročilém logování v Application Insights. Registrujte se zdarma a přijďte se podívat, třeba jen na pár přednášek.
Před pár dny byla vydána nová verze JetBrains Rider a s ní několik zajímavých funkcionalit. Rider používám na denní bázi a většinu z nových funkcí jsem měl již možnost vyzkoušet. V tomto článku se na ...
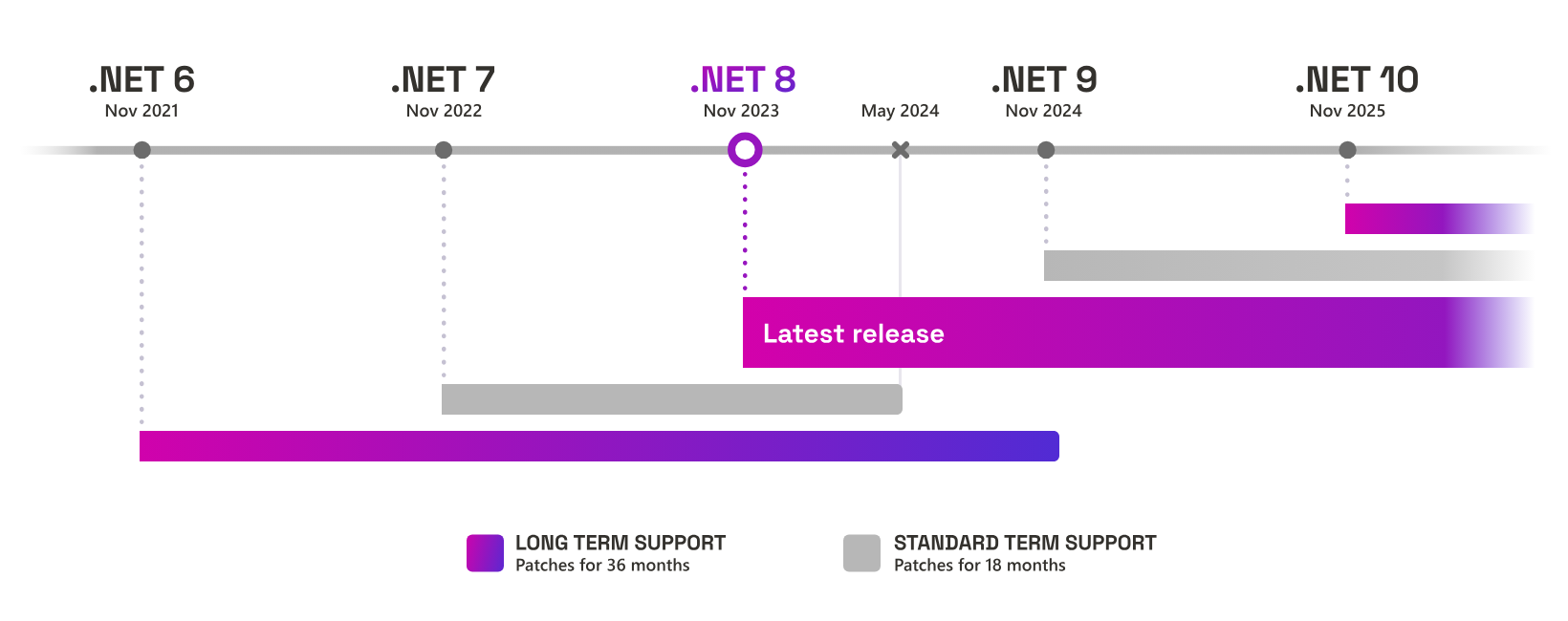
Microsoft ukončuje podporu .NET 7
Přesně za měsíc (14. května 2024) Microsoft přestane servisovat .NET 7. Tato verze byla vydána v rámci tzv. standard term supportu s podporou 18 měsíců. Co to znamená pro vaše aplikace? Aplikace, které běží v bezpečí firemní infrastruktury můžete nadále provozovat i bez supportu. Je-li pro vás zabezpečení důležité nebo běží-li aplikace veřejně, měla by být zmigrována na aktuální .NET 8. Ten bude záplatován až do konce roku 2026. Pro dosluhující .NET 7 již nebudou od 14 . května vydány žádné (ani bezpečnostní) záplaty.
Chcete migrovat na .NET 8 a potřebujete se zorientovat v novinkách? Využijte mé školení Novinky v .NET 8 a C#.
Oblast umělé inteligence by měl alespoň periferně sledovat každý vývojář. V záplavě nezajímavých zpráv a tun zbytečných nástrojů se totiž občas objeví i důležitá sdělení nebo aplikace. Připravil jsem ...
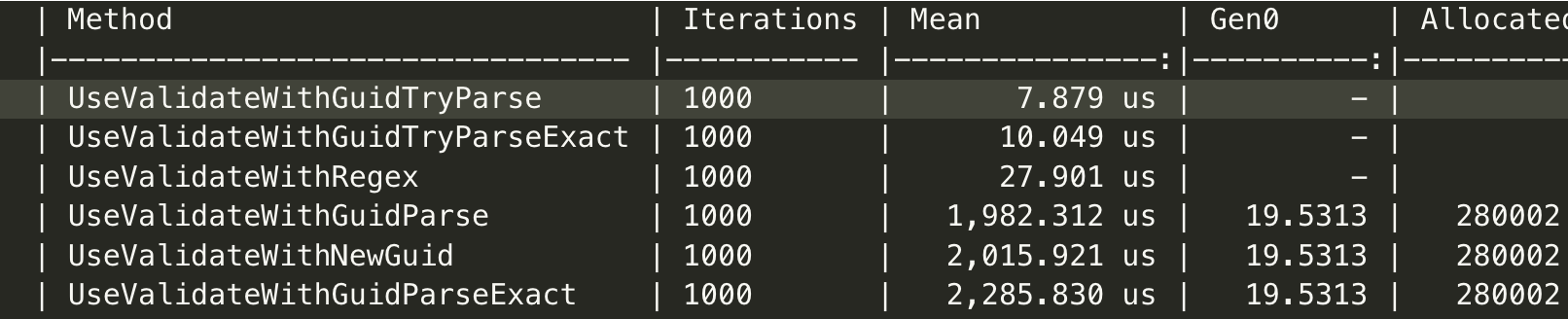
Jak nejlépe validovat GUID
Jak validovat GUID? Krátký článek od Osman Sokuoglu popisuje typické metody a výkonnostní rozdíly. Dle očekávání nejlépe vychází použití TryParse metod nebo regulárních výrazů. V případě regulárních výrazů pak novinka z .NET 8 (Generated Regex). Zajímavé ale je, jak velmi neefektivní jsou ostatní metody.
Jednoduché, čitelné a výkonnostně optimální je obyčejné řešení:
Guid.TryParse(input, out Guid _);
Měření response time u Blazor SSR
Jak měří Application Insights v Blazoru zapnutý SSR [StreamRendering]? Dle očekávání se čeká na dokončení celého streamování, takže celkový response time odpovídá finální vykreslené verzi HTML. Čas prvního naservírování HTML si musí každý změřit sám.

Možná máte CODE Magazín zdarma
Zdaleka ne každý vývojář ví, že má přístup k magazínu CODE. Ten standardně stojí 20 USD ve své digitální verzi. Přístup zdarma máte tehdy, pokud vlastníte Visual Studio Dev Essentials subscription. Zjistíte to na stránce my.visualstudio.com. Magazín vychází každé 2 měsíce a je ke stažení nejen v PDF, ale i jako MOBI nebo si ho lze přečíst online. Verze PDF vypadá nejlépe.
Já už jsem zapomněl, že přístup mám. Aktuální číslo je obsahově docela slabé.

Klient RedisInsight pro správu Redis
Na mnoha projektech používám Redis a před pár dny jsem objevil pěknou náhradu za dosavadní dosluhující Redis Desktop Manager. Klient RedisInsight nabízí moderní GUI, podporuje Azure Redis a má vestavěný CLI i profiler. Ke stažení je pro všechny platformy zdarma.
Technologie pro vývoj webových aplikací od Microsoftu si prošly dlouhým vývojem. Od ASP, přes WebForms a MVC až po současný ASP.NET Core, který podporuje několik přístupů k tvorbě webu. Zatímco třetí ...
Praktické zkušenosti s Blazor SSR
Jak jste si všimli, celý můj web je v novém kabátě. Používám technologii Blazor SSR vydanou v NET 8. Rád bych v bodech nasdílel pár postřehů z praktického programování.
- Obecně je SSR naprosto geniální. Kliknutí na odkazy odchycuje JS, ten pošle požadavek na server. Server vyrenderuje novou verzi webu a JS provede aktualizaci DOM, takže se nepřekresluje celá stránka. Při zapojení Stream Renderingu je navíc možné zobrazit spinner, než se načtou data. Nemám to všude, protože ještě ověřuji, jak se k tomu zachovají vyhledávače.
- Navigation Manager vyžaduje konkrétní URL v aplikaci, takže je snadné udělat překlep. V případě jazykových verzí by se asi musel Navigation Manager upravit.
- Při odkazování na obrázky se nepoužívá vlnka
(~/img.jpg), takže i zde chybí přirozená kontrola existence souboru ve wwwroot.
- Scrollování při přecházení mezi stránkami je navržené špatně. Microsoft si to žehlí tím, že údajně ve Vue to funguje podobně blbě. Naštěstí to lze řešit workaroundem (mrkněte na JS kód na tomto webu)
- Systém komponent je opravdu super. Hodně se mi osvědčilo spojení komponenty + vlastních CSS stylů. Výhoda je, že každá sebemenší komponenta si může nezávisle načítat data na základě parametrů, které předám zvenku. Jsou to partial views na steroidech.
- Na stránce fungují mizerně kotvy (#). Respektive funguje to při zobrazení nové stránky, ale pro pohyb na stránce je používat nejde. Co víc, Blazor v takovém případě posílá uživatele na úvodní stránku.
- Při stavbě FORM je potřeba hlídat si strukturu HTML. Nějak se mi stalo, že se mi do P vygeneroval DIV s alertem a v enhance módu mi to pak ten DIV z odstavce vyhodilo.
- Atribut
[SupplyParameterFromQuery] nebyl ochotný vzít číselnou hodnotu a zparsovat ji na řetězec. Opačně bych to chápal, ale není dobré mít v query parametru něco, co může mít hodnotu jako řetězec i číslo. Třeba telefonní číslo "773272767" vs "+420..." už může být problém.
- Když mám prvek
InputSelect ve formuláři, tak se mi nevybere automaticky správná OPTION při two-way bindingu. U Blazor Server to fungovalo. Musím tedy ručně přidat vlastnost "checked" a hodnotu true/false dopočítat.
- Zatím jsem nenašel způsob, jak zapojit efektivně Application Insights JS SDK. Připravený kód od MS automaticky dělá
TrackPageView(), ale tato událost logicky nenastane při klikání na jiné stránky, protože se neobnovuje celá stránka, ale pouze se aktualizuje DOM. Zatím mám AI pouze na serveru. Řešením bude najít nějaký init script a dát ho do App a v App pak reagovat na událost "enhanceload" a v této události zavolat TrackPageView().
- Při zastavení aplikace nebo rekompilaci obecně dochází k nějakému záseku. Dlouho mi svítí Application Is Shutting Down, takže vynucuji vypnutí. Děje se to i po update JetBrains Rideru, takže to bude asi něco v tom SSR.
Microsoft vydal 11. listopadu další verzi frameworku .NET 8 a s ní představil mnoho zajímavých novinek. Kromě výkonnostních vylepšení a mnoha drobností v .NETu a C# došlo také k zásadním inovacím webo...
V tomto článku sepisuji mé postřehy ke službám OpenAI a Azure OpenAI service a k různým SDK, které lze pro komunikaci používat. Tento článek není recenze, ale pouze pár postřehů z praxe. Článek se bud...
Na několika mých přednáškách jsem v poslední době ukazoval velmi jednoduchý způsob, jak přijímat platby. Protože PayPal nabízí celou řadu platebních nástrojů, záludné je především najít v dokumentaci ...
V červenci společnost OpenAI oznámila obecnou dostupnost GPT-4. Od oznámení ještě trvalo poměrně dlouhou dobu, než se GPT-4 reálně každému zpřístupnil, ale dnes už je cesta k tomuto modelu poměrně sna...
Přestože aplikací založených na AI (artificial intelligence) existuje již delší dobu mnoho a sám Microsoft vývojářům v Azure dlouhé roky poskytuje zajímavou sadu Cognitive Services, skutečný zájem o A...
Přestože aplikací založených na AI (artificial intelligence) existuje již delší dobu mnoho a sám Microsoft vývojářům v Azure dlouhé roky poskytuje zajímavou sadu Cognitive Services, skutečný zájem o A...
Od května pracuji na uvolnění mých kapacit a nyní mohu s radostí potvrdit, že nyní dochází k výraznému zkrácení čekání na školení. Konzultace budu nyní schopen poskytnout v řádu hodin, termíny standar...
Každá nová verze .NETu dokáže trochu zamíchat kartami a přinutí mě udělat menší či větší množství zásahů do školení. Poslední verze .NETu patří k těm umírněnějším. Na základě prvních měsíců školení no...
JetBrains je česká společnost, která se již přes 20 let věnuje vývoji software pro vývojáře a management. Výkonný ředitel Maxim Shafirov je původem z Ruska, stejně jako původní zakladatelé Dmitriev, K...