
Cachování v .NETu
Tento článek byl napsán v roce 2022. Vývojářské technologie se neustále inovují a článek již nemusí popisovat aktuální stav technologie, ideální řešení a můj současný pohled na dané téma.
Cachování je ve své zásadě jednoduchý mechanismus, který je často zdrojem mnoha chyb v aplikacích. Nešikovně nastavené cachování způsobuje nekonzistence, vytváří prostor pro vznik těžko dohledatelných chyb a může způsobit i únik osobních dat nebo jiné problémy v souvislosti se zabezpečením. Cachovat správně není vůbec jednoduché a vytvářet robustní řešení stojí cenný čas. Když se zadaří, odměnou nám je lepší výkonnost aplikace. Jediný a často klíčový benefit.
Co je cachování?
Pojem cache zná zřejmě každý vývojář. Každý si pod tím ale představuje něco trochu jiného. Ve své podstatě je cachování mechanismus, při kterém strčíme mezi proces a pomalé úložiště nějaké rychlejší úložiště (mezipaměť), odkud si může proces data vyzvednout.
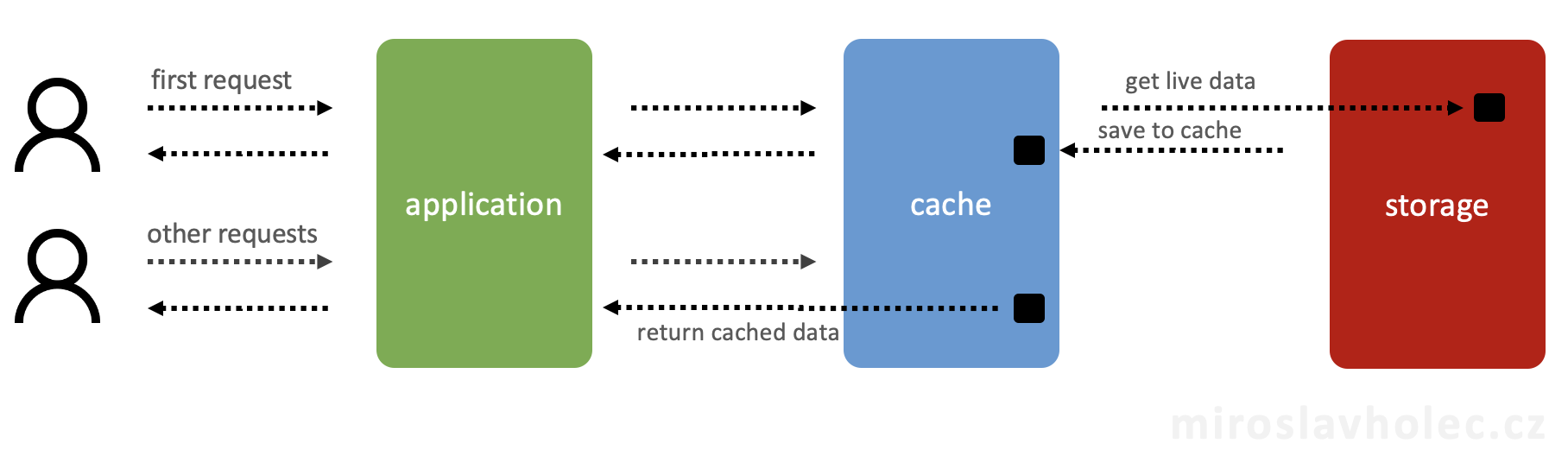
Scénářů, kde můžeme použít cachování je nespočet. Primární motivací je zlepšení výkonnosti aplikace. V závislosti na použitých technologiích a scénáři lze výjimečně i ušetřit pár korun. Takových situací je ale jako šafránu. Chcete-li dopřát uživatelům aplikace lepší prožitek při používání aplikace, cachování může být vhodná cesta.
Je důležité zvážit:
- co vše a jakým způsobem můžeme v aplikaci cachovat
- jaká jsou rizika spojená s chybami při cachování
- jak velký vliv bude mít cachování na výkonnost aplikace
- jak velký zásah musíme do aplikace udělat
Nezřídka můžete zjistit, že architektura aplikace je navržena tak, že implementace cache bude časově náročná a pravděpodobně ne prostá chyb. Pak stojí za zvážení, zda výkonnost aplikace nedoženeme jinak: naškálováním strojů, optimalizací kódu, výměnou datového úložiště, atd.
Rychlé úložiště
Zmínil jsem, že při cachování se používá rychlé úložiště. Workflow u standardního cachování je založeno na několika krocích, které proces vykoná:
- podívej se, zda jsou v cache připravena data
- pokud data připravena nejsou, získej čerstvá běžným způsobem
- pokud jsi načetl čerstvá data, ulož je do cache
- vrať data
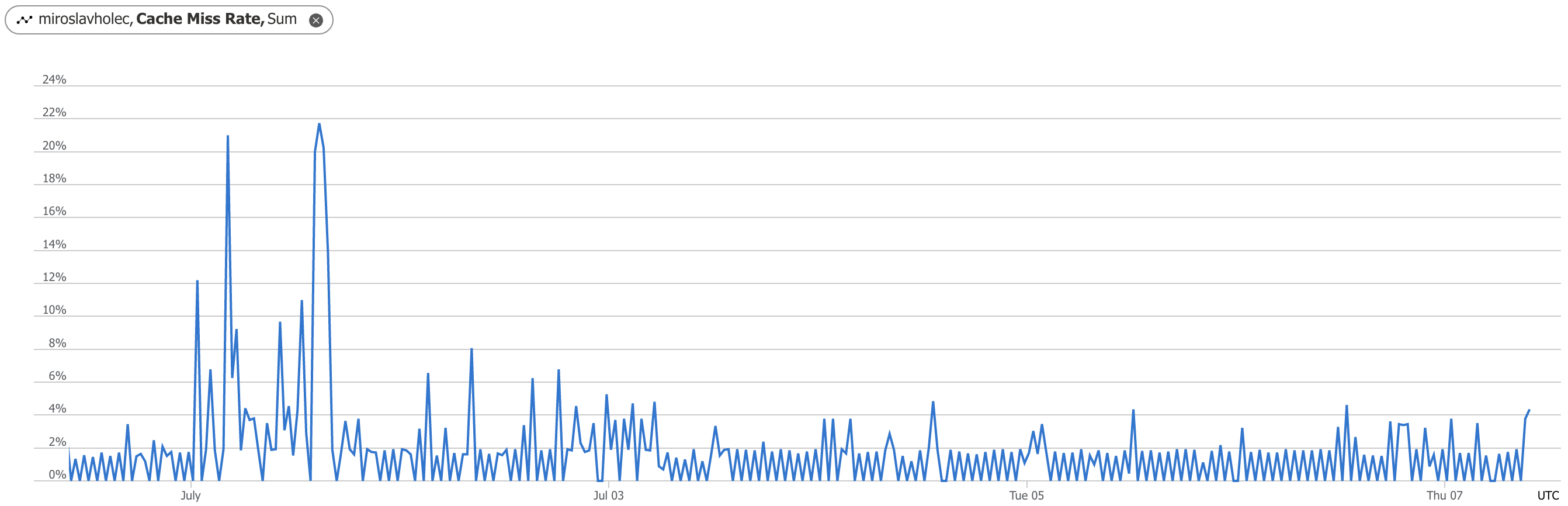
Každý z výše uvedených kroků skrývá určitá rizika a nevýhody. Například "podívej se do cache" znamená bez ohledu na rychlost mezipaměti dodatečný krok, který stojí dodatečný čas. Pokud by proces získal data z mezipaměti jen zřídka, pak by se celé řešení naopak zpomalilo. A to není celé, protože ve třetím kroku "ulož čerstvá data do cache" opět požíráme čas procesu. Poměr mezi úspěšným a neúspěšným čtení z cache je důležitý ukazatel. Z toho vyplývá, že i situace zcela vhodná pro implementaci cache nemusí v případě aplikace fungovat. Když bude daný scénář průchodný malým množství uživatelů, pravděpodobně to žádný velký přínos mít nebude. Níže je například vidět nízký "cache miss rate" na mém webu. Průměrně jen 2 % případů jsou neúspěšná. Na grafu jsou vidět i vrcholy spojené s nasazením aplikace a pročištěním cache, které je typické u jedné části mého webu.
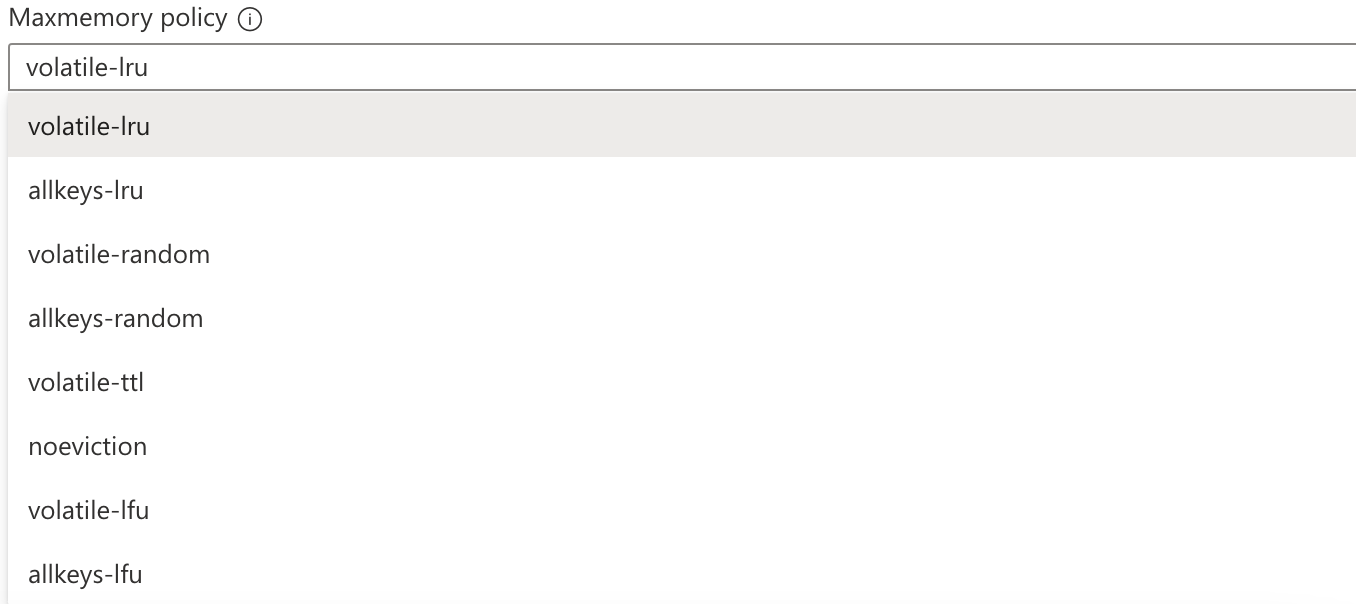
Z výše uvedeného popisu je zřejmě, že přístup do cache není zdarma a proto chceme, aby mezipaměť byla skutečně rychlá. Čím je mezipaměť rychlejší, tím je bohužel pro peněženku provozovatele i dražší. Zlatým standardem je operační paměť. Ta se ale rychle zaplní a vzniká další zajímavá otázka: jak ji udržet čistou? Existuje hned několik strategií, co dělat se zaplněnou cache. Kterou ale zvolit? Vyhodíme objekty, které se nepoužily nejdelší dobu? A nebo objekty, ke kterým se přistupuje nejméně? A nebo objekty, které už beztak za minutu přestanou být aktuální? A nebo objekty, které jsme do cache vložili v nejvzdálenější minulosti?
Tím ale záludnosti nekončí. Samotný proces uložení do cache může být také oříšek. Co když úložiště neumí ukládat běžný C# objekt? Pak často přichází na řadu ruční serializace. Uložíme to v JSONu nebo použijeme rychlý Protobuf serializer? JSON je totiž čitelnější a můžeme ho rovnou vrátit z aplikace. A je vůbec dobrý nápad ta data ukládat v čitelné formě nebo je raději nejprve zašifrujeme?
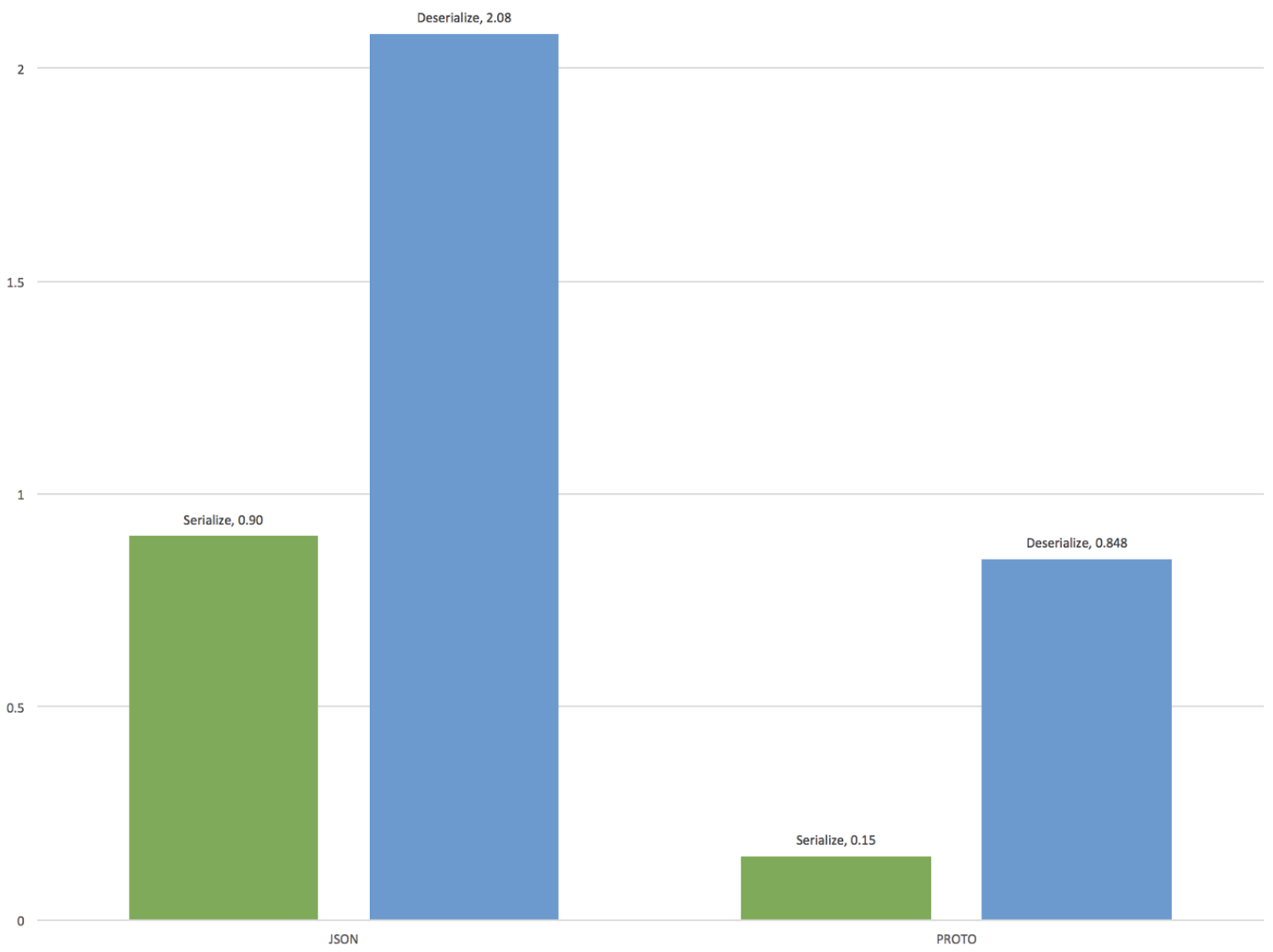
A když budu cachovat, serializovat a šifrovat, má to ještě výkonnostní benefit? A hlavně... co když se data změní? Jak dlouho mají být data v cache? Má to být statický čas a nebo lze zvolit nějakou jinou strategii? Jak nejlépe invalidovat cache? Neaktuální data v mezipaměti mohou přeci způsobit nekonzistence. Ale jak řešit vazby mezi objekty v cache?
Druhy cachování
S cachováním se pojí mnoho důležitých otázek. Doposud jsme se ale zabývali aplikační mezipamětí. Ne vždy ale chceme ukládat data do operační paměti na stejném stroji, který odbavuje HTTP požadavky aplikace. Co když běží aplikace na více strojích? Duplicitní cachování a složitý proces invalidace není jednoduchý. Zažil jsem aplikaci, kde se invalidovala data přes service bus. Uff, to už nechci zažít.
Můžeme nastavit traffic manager, aby vytvářel affinity cookies a posílal uživatele stále na stejnou mašinu. Ale to nebude tak dobře škálovat. A hlavně to není RESTful. Takže pak přichází na řadu distribuované cachování. Ale co si vybrat? Memcached nebo Redis? Počkat. Když jsme se bavili o těch JSONech, není už tedy lepší použít MongoDB? A co se na tu cache teda vykašlat a místo relačního úložiště to narvat do dokumentové DB. Není to kompromis?
Že už to začíná být složité? To jsme stále na začátku. Máme totiž ještě HTTP cache, která je založená na emitování HTTP hlaviček webovým serverem. Nechceme přeci, aby si webový prohlížeč neustále načítal CSS styl stránky, který se mění jednou za uherský rok. No a pak je tu DNSka. Web tahá obrázky a styly z několika serverů. Nešlo by prohlížeč instruovat, aby si při návštěvě jednoho resolvnul DNSku těch ostatních? Jasně, že to jde. A co to neustále přesměrování z HTTP na HTTPS? No jasně , na to má přeci .NET middleware. Moment, a co když přijde request z USA? Nešlo by ty statické soubory servírovat odjinud než z Pelhřimova? I to by šlo, protože naštěstí tu máme CDNku.
Pozvánka na webinář
Přiznávám. Do článku se to nevejde. Mě už bolí ruka od psaní a vás určitě oči od čtení. S cachováním se pojí celá řada možností, které stačí znát. Už to, že o nich budete vědět stačí k tomu, abyste je jednoho dne zapojili do aplikace. Proto jsem se rozhodl na téma cachování udělat webinář. Budeme mít tři hodiny, během kterých si ukážeme všechny možnosti cachování v moderních aplikacích.
| Webinář | Cachování v .NETu a Redis Cache |
| Termín | 20. července 2022, 14 - 17 hod |
| Registrace | registrace zde |