
Inspirace jak stáhnout články z Tumblr a konvertovat je do Markdown
Tento článek byl napsán v roce 2018. Vývojářské technologie se neustále inovují a článek již nemusí popisovat aktuální stav technologie, ideální řešení a můj současný pohled na dané téma.
Během cestování jsem zvyklý dělat si zápisky, ke kterým se mohu později vracet a vzpomenout si snadno na různé zajímavé okamžiky. Pro cestu JV Asií, na které jsem strávil 100 dní jsem se rozhodl použít Tumblr. Jedná se o webovou službu, která nabízí mimo jiné i mobilní aplikaci pro iPhone, díky které je možné pohodlně psát vlastní blog a okamžitě tak sdílet svou cestu s přáteli. Svůj klasický blog mám ale naprogramovaný po svém a používám markdown syntaxi. Jak tedy udělat export celého tumblr blogu do markdown souborů?
Jak funguje můj cestovatelský web
Můj cestovatelský weblog mirekholec.cz funguje na základě práce se soubory v syntaxi markdown. Ve své podstatě mohu kdykoliv v počítači psát článek offline v markdown editoru, připojovat si různé obrázky do předem definované složky a konečný výsledek uložit do Azure Blob Storage. Struktura pak vypadá následovně:
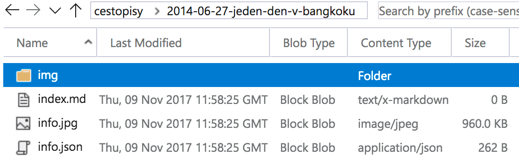
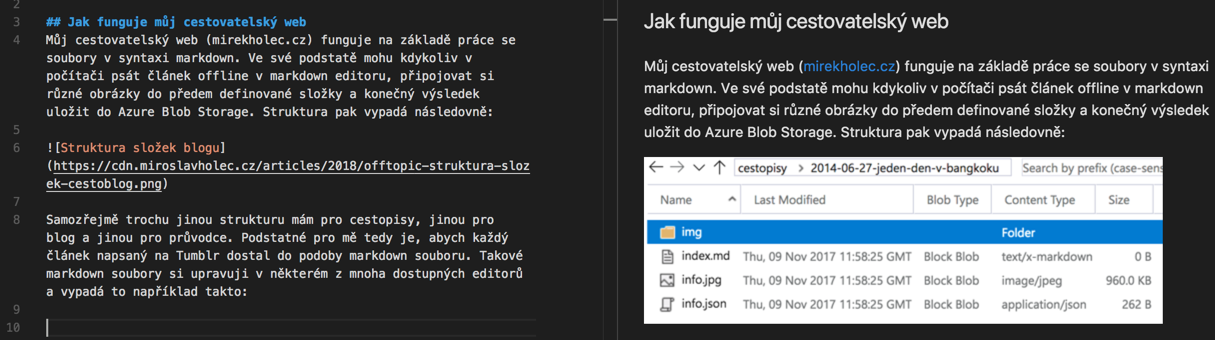
Samozřejmě trochu jinou strukturu mám pro cestopisy, jinou pro blog a jinou pro průvodce. Podstatné pro mě tedy je, abych každý článek napsaný na Tumblr dostal do podoby markdown souboru. Takové markdown soubory si upravuji v některém z mnoha dostupných editorů a vypadá to například takto:
Azure Logic Apps - stažení dat z Tumblr do vlastní databáze
První služba, kterou jsem použil pro přenesení článků byla Azure Logic Apps. Díky ní jsem sestavil jednoduché workflow, které se mi podívalo na Tumblr blog a stáhlo si všechny články pomocí API do mé SQL databáze.
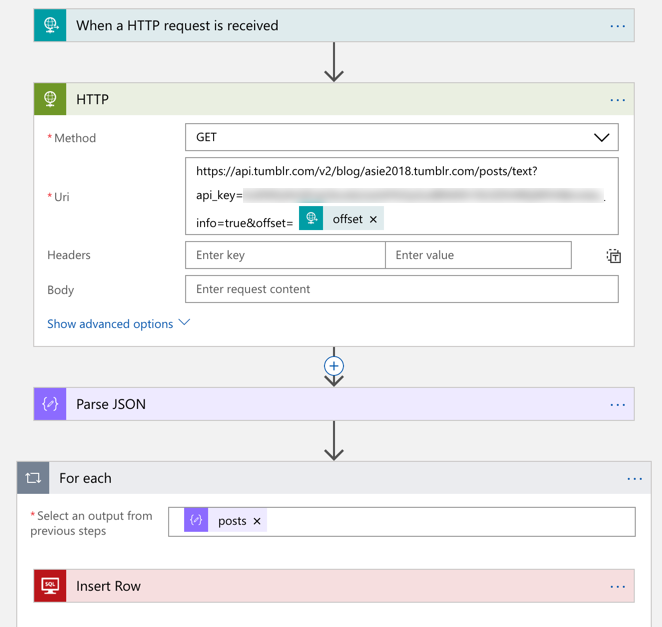
Z obrázku je patrné, že si ručně hitnu URL, kterou mi služba Logic Apps vyrobila a poté:
- zavolám tumblr API a požádám o vrácení článků
- data se mi vrátí jako JSON, který následně zparsuji
- pro každý jeden článek poté založím v databázi nový řádek do dočasné tabulky.
Skvělé na tom je, že nemusím psát žádnou složitou aplikaci. Všechno si naklikám za pár minut v jednoduchém vizuálním prostředí.
Konverze HTML na Markdown
Všechny články si uchovávám v souborech v markdown syntaxi a tyto soubory se později překládají do HTML (zobrazení na webu). V tomto případě již sice HTML mám, nicméně chtěl bych mít stále stejné workflow a tudíž si chci všechny HTML převést na markdown. Pro tento účel jsem si napsal klasickou konzolovku v .NETu, která si sahá na každý řádek v databázi, a poté:
- vezme HTML a převede jej na MD
- uloží MD do speciálního sloupce v databázi
- následně převedu titulky do SEO podoby (dále linky)
- následně si vyrobím samostatné markdown soubory na disku
Pro převedení HTML do Markdown jsem použil knihovnu Html2Markdown dostupnou na GitHubu a v podobě NuGet balíčku. Soubory mám pojmenované dle linku (původně titulek) + ".md".
Doplnění diakritiky
Psát články na mobilu je něco, do čeho už bych se podruhé nepouštěl. Vytvoření delšího článku mi bezproblému zabralo i 2 hodiny a to neberu v potaz, že všechny články jsou bez diakritiky. Abych dostal články do formy, tak jsem se rozhodl diakritiku přidat. Jako řešení, které mi trochu usnadnilo život je projekt z Laboratoře zpracování přirozeného jazyka s názvem ohákování. Díky této jednoduché webové aplikaci není problém vložit text bez diakritiky a získat jej zpět diakriticky obohacený. Samozřejmě to má plno much a mušek, ale i tak mě to přibližuje ke konečnému výsledku.
Všechny MD soubory jsem nakonec ručně prošel a upravil všude, kde se něco nepovedlo. Typicky ne vždy se podařilo doplnit diakritiku na správná místa. Ohákování občas zafungovalo i na cesty k obrázkům nebo na HTML tagy :)
Stažení obrázků
Posledním krokem by bylo stažení obrázků z Tumblr. To by neměl být problém, nicméně rozhodl jsem se do toho zatím nepouštět a obrázky si k blogpostům připojit ručně z mých alb. Důvodem je nízká kvalita obrázků uložených na Tumblr a také to, že plno článků chci doplnit o další obrázky, které původně v blogpostech nebyly.
Pokud byste chtěli tento krok automatizovat, mělo by stačit jen projít obsah všech blogpostů a pro každý vyhledat obrázky, stáhnout je do filesystému a poté změnit začátek cesty k obrázku (např.: místo http://www.tumblr.com/img/a/b/c.jpg udělat http://www.mujweb.cz/path/a/b/c.jpg.
Proč tolik práce?
I když zpracování článků z Tumblr vypadá složitě, ve skutečnosti si to mou práci a čas zaslouží. Zápisy z cest jsou pro mě neskutečně cenné a na cestách jsem jim věnoval velké úsilí. Během 100 dní v Asii jsem strávil psaním článků asi 80 hodin, což jsou vlastně téměř 4 čisté dny bez spánku. Navíc všechen tento učesaný obsah chci zformovat do vlastní knihy. Pro představu ještě uvádím odkaz na původní blog asie2018.tumblr.com a aktuální skoro výsledek na mém novém blogu na destinaci kanchanaburi.