Programy a skripty v C# bez csproj v .NET 10
Platforma .NET nesla ve světě vývoje vždy určitou pachuť korporátnosti. Ještě před pár lety šlo vytvořit nový projekt prakticky jen na Windows s pomocí těžkopádného Visual Studia, které si běžný stude...
 Miroslav Holec
Miroslav Holec
Platforma .NET nesla ve světě vývoje vždy určitou pachuť korporátnosti. Ještě před pár lety šlo vytvořit nový projekt prakticky jen na Windows s pomocí těžkopádného Visual Studia, které si běžný stude...
Ztrpčovat život uživatelům Windows zvládá Microsoft už dlouhé roky. Nově se mu ale daří otravovat i ty, kteří používají macOS nebo Linux, například pomocí služby AutoUpdate.
Upload souborů v Blazoru je obecně zajímavá disciplína, protože každý režim fungování (SSR, Server, Wasm) vyžaduje odlišný přístup. V případě Blazor SSR není k dispozici žádná interaktivita a tudíž je...
Od roku 2014 sepisuji přehled oblíbeného software a nástrojů, které používám nejen pro vývoj aplikací, ale celkově pro mou práci. Poslední roky jsem seznam neaktualizoval, takže nyní nadešel čas na ve...
Před přibližně třemi lety jsem dokončil svého průvodce designem REST API. Mým cílem bylo vytvořit textovou verzi mého školení, která by ho v některých aspektech doplnila a rozšířila. Jako ideální form...
Pojem elektronický podpis s sebou pro běžné uživatele nese často hořkou pachuť. Sám o sobě je totiž tento pojem velmi obecný a zahrnuje celé spektrum způsobů, kterými lze ověřit totožnost podepsané os...
Až donedávna jsem považoval Stoplight za nejlepší (a jediný) UI nástroj pro návrh REST API. Před několika měsíci mi jeden z účastníků školení zmínil aplikaci Apidog. Zapsal jsem si ji a před pár týdny...
Konečně jsem se dostal k aktualizaci mých 7 menších aplikací. Až na jednu výjimku vše proběhlo hladce a téměř celá smečka webů běží na .NET 9 a EF Core 9. Podle výsledků v produkci mi bude zbývat migr...
Při přípravě nového školení .NET 9 si tradičně vytvářím vlastní snímky, nicméně občas potřebuji podívat se do prezentací z poslední konference .NET Conf nebo porovnat změny v posledních verzích.
Zde je .NET Conf GitHub s odkazem na konkrétní repositories. Níže pak poslední roky
| Event | Date |
|---|---|
| .NET Conf 2024 | November 12-14, 2024 |
| .NET Conf Focus on AI | August 20, 2024 |
| .NET Conf 2023 | November 14-16, 2023 |
| .NET Conf 2022 | November 8-10, 2022 |
Pro dnešek mám velmi rychlý tip. Nedávno byl zveřejněn LINQPad pro macOS a tím pádem jsem se po letech vrátil k vytváření snippetů s pomocí tohoto programu. Naprosto excelentní je to pro účely mých školení. Snippety se ale uchovávají jako soubory s příponou linq.
Jak zajistit, aby se mi linq soubory ve VS Code obarvily jako C#? Asi nejlepší řešení je spustit si vyhledávání v nastavení (CTRL + SHIFT + P) a zadat Preferences: Open User Settings (JSON). Tím se otevře soubor settings.json, kde už stačí asociovat příponu souboru s vybraným jazykem.
{
"files.associations": {
"*.linq": "csharp"
}
}
A je hotovo.
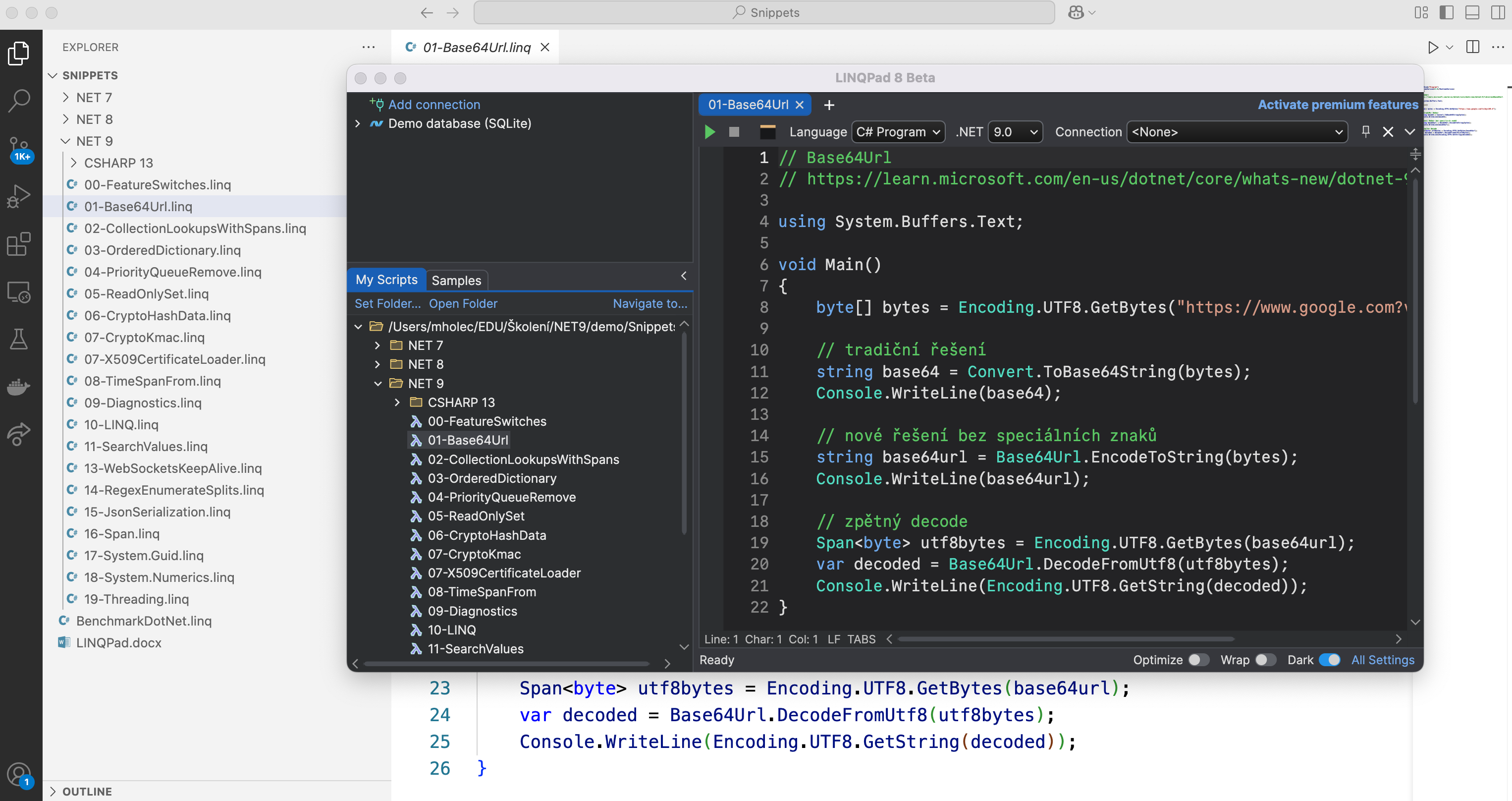
I tento rok jsem aktualizoval přehled zajímavých licencí a předplatných, které jsou aktuálně dostupné v Black Friday slevách. V přehledu se zaměřuji především na software a to si menším přesahem.
Každý rok se snažím zmapovat u mých followers zájem o různé technologie a podle toho určit strategii mé práce na další rok. I tento rok se podařilo sesbírat několik desítek odpovědí z mé malé sociální...
Poslední neprozkoumaná oblast Blazoru pro mě byla donedávna Blazor Hybrid. Zatímco Blazor Server běží na serveru a Blazor WebAssembly v prohlížeči, Blazor Hybrid je zahostován v komponentě BlazorWebVi...
I tento rok se koná mnoho zajímavých akcí. Pro přehlednost jsem vytvořil tabulku vybraných konferencí a událostí na podzim 2024. Pod tabulkou dále uvádím vlastní komentář. Bližší informace o akcích pl...
Blazor doznal ve verzi .NET 8 zásadních změn, díky kterým se stal velmi univerzální technologií pro stavbu webových aplikací. V tomto článku bych chtěl nastínit několik záludností, na které se doporuč...
Byl jsem hostem nové epizody podcastu ProgramHRování. S Vojtou a Šárkou jsme rozebrali spoustu zajímavých témat třeba k čemu je dobré mít IT konzultanta nebo aktuální stav .NET světa. Máte se na co těšit!
Epizodu si můžete poslechnout níže nebo na všech podcastových platformách. Bonusová část je na Forendors podcastu ProgramHRování.
Před pár dny jsem dostal zpětnou vazbu k mému Premium a k webu. Součástí byl i zajímavý podnět, že by nebylo špatné přidat do Premium účtu dark mode (tedy tmavý režim). U videa to pochopitelně už nezm...
Dnes jsem byl již osmý rok po sobě oceněn jako Microsoft MVP za přínos vývojářské komunitě. Za poslední rok jsem připravil více než 10 přednášek zaměřených na .NET, REST API a Blazor. Přednášel jsem pro WUG v Praze, Brně i ve Zlíně. Vytvořil jsem mnoho video obsahu, který najdete na mém YouTube kanále. Oživil jsem také podcast Háčko, který můžete poslouchat například na Spotify. Také jsem rozšířil můj Blog zde na webu. Nově tu najdete i různé technologické ukázky a code snippety. Nadále vydávám občasník Dotnet News,který můžete zdarma odebírat.
Od minulého měsíce natáčím nová videa do Premium sekce ve 4K kvalitě, kterými doplňuji má nejoblíbenější školení. Jedná se o témata související s .NET vývojem, návrhem a vývojem REST API a s technologií Blazor. To jsou zároveň klíčová školení, která neustále aktualizuji a doručuji do dnes již více než 200 firem.
Stream Rendering je power feature v Blazoru. Všude funguje spolehlivě, ale v Azure App Service z neznámého důvodu ne. Po delším zkoumání jsem zjistil, že podobný problém má v různých situacích mnoho vývojářů. Když Stream Rendering nefunguje, čeká se na provedení celé metody OnInitializedAsync a teprve poté se aktualizuje DOM finálním HTML.
Jednotný lék je přenastavit Content-Encoding. Na začátek middleware pipeline jsem tedy přidal middleware, který hlavičku nastaví (nemá to dále nemá vliv na statické soubory, API response atd.). Hodnota identity indikuje, že se žádná komprese nepoužije.
Update 9.1.2025 - po zapojení nového StaticAssets middleware (v .NET 9) skrze MapStaticAssets() je nutné přidat podmínku, zda se nepoužívá komprese. Je to tu kvůli gzip & brotli kompresi u statických souborů.
public class ContentEncodingMiddleware(RequestDelegate next)
{
public async Task InvokeAsync(HttpContext context)
{
var encoding = context.GetEndpoint()?.Metadata.GetMetadata<ContentEncodingMetadata>();
if (encoding == null)
{
context.Response.Headers.Append(HeaderNames.ContentEncoding, "identity");
}
await next(context);
}
}
Pokud někdo něco podobného řeší, další přičinou může být i response buffering, který je pro stream rendering též nežádoucí.
Blazor přinesl do .NET 8 naprosto zásadní změny. Na základě komunikace s vývojáři jsem se rozhodl koncept mého školení upravit do takové podoby, aby si každý tým přišel na své. Zkrátka univerzální tec...